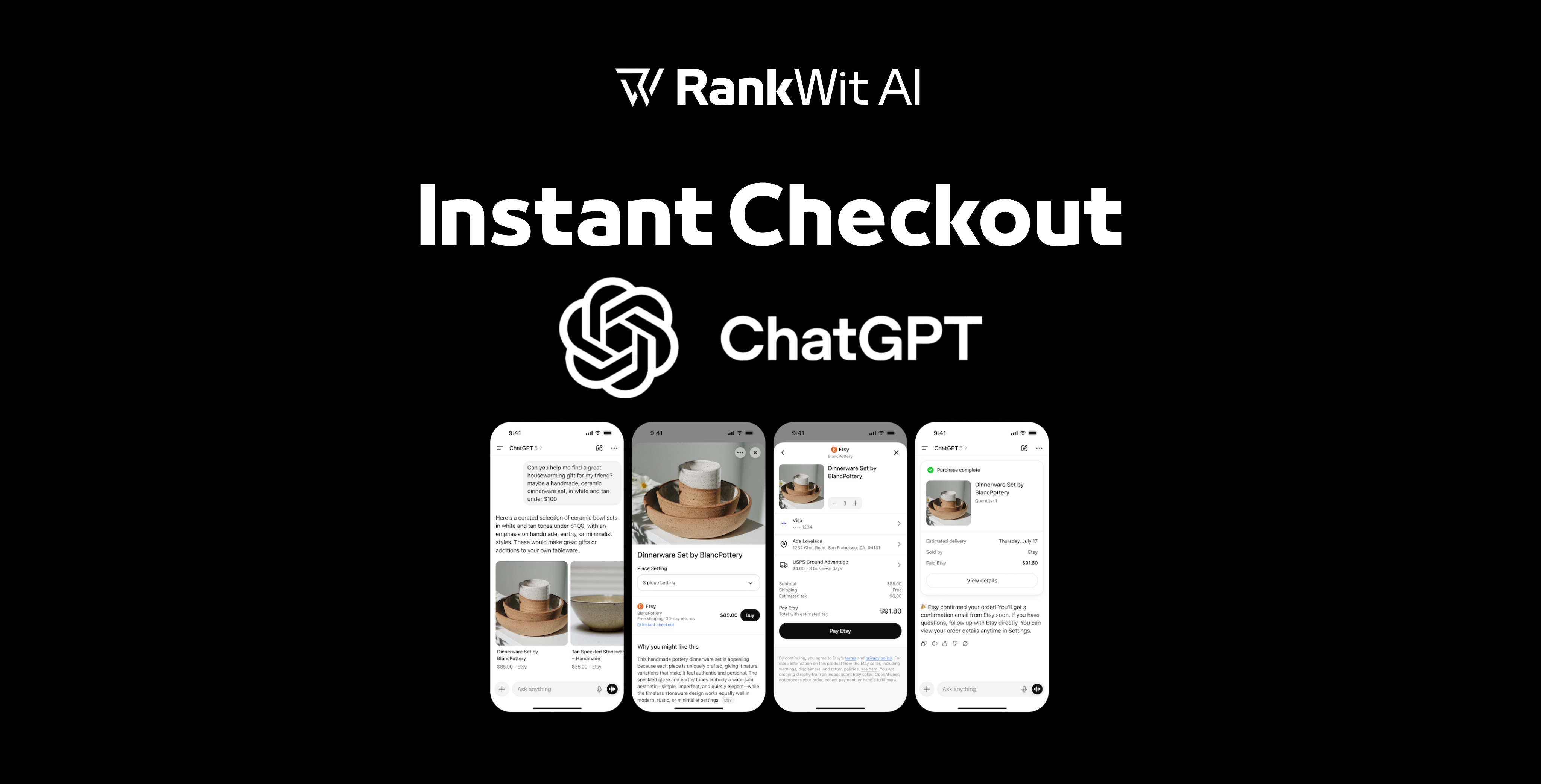
Tokenizzazione è il processo mediante il quale i modelli di intelligenza artificiale, come GPT, suddividono il testo in piccole unità, chiamato gettoni—prima dell'elaborazione. Questi token possono essere piccoli come un singolo carattere o grandi come una parola o una frase. Ad esempio, la parola «commercializzazione» potrebbe essere un token, mentre «Strumenti basati sull'intelligenza artificiale» potrebbe essere suddiviso in più parti.
Perché è importante per GEO (ottimizzazione generativa del motore)?
Perché il grado di tokenizzazione dei tuoi contenuti influisce direttamente sulla precisione con cui vengono compresi e recuperati dall'intelligenza artificiale. Una scrittura mal strutturata o eccessivamente complessa può confondere i confini dei token, con conseguente mancanza di contesto o risposte errate.
✅ Linguaggio chiaro e conciso = migliore tokenizzazione
✅ Titoli, elenchi e dati strutturati = più facili da analizzare
✅ Terminologia coerente = migliore richiamo dell'IA
In breve, ottimizzare per GEO significa scrivere non solo per i lettori o i motori di ricerca, ma anche per come funziona l'IA tokenizza e interpreta i tuoi contenuti dietro le quinte.
.svg)